
By Nishikant Dhanuka, Senior Director of AI at Prosus Group
At the beginning of February, 100 agent builders from across the Prosus portfolio gathered at AI House Amsterdam for our first-ever Agent Bootcamp. The goal: accelerate our agent roadmaps to deliver real business results. While building an agent is easy, getting one to work reliably in production at scale is where the real work begins. Nishikant Dhanuka, Senior Director of AI at Prosus Group, shared his perspective on the state of AI agents and where they're heading.
A year ago, the conversation across the AI industry centered on the question: which is the smartest model? Today, the conversation has shifted to something far more consequential: for how long can your agent work autonomously before it breaks? This transition from one-shot intelligence to endurance, from conversational AI to genuine autonomy, is the defining narrative of 2026. And much of the industry is still grappling with what this shift truly means.
2025: The Year Agents Grew Up
2025 was a phenomenal year for AI agents, marked by several inflection points that compounded on each other. The year began with the DeepSeek moment, which democratised reasoning models—for the first time, we could see a model's thinking tokens separate from its output, enabling agents to plan before acting.
Soon after, Model Context Protocol (MCP) became the standard for agent-tool integration. Claude Code and other agentic Integrated Development Environments (IDEs) shifted how developers work, with many now spending more time in the agent panel than the code panel. Agentic browsers emerged, transforming the browser from a page-fetching tool into an agent capable of performing web tasks autonomously. If 2024 was the year of prompt engineering, 2025 became the year of context engineering.
The year concluded with OpenAI and Stripe's Agentic Commerce Protocol moving agents beyond information retrieval into real transactions, and two frontier models built specifically for agentic work: Claude Opus 4.5 and GPT 5.2. These models weren't built for chat – they were built for developers and agent builders. The benchmarks reflect this shift: agentic coding, terminal coding, tool use, computer use. These aren't chat benchmarks measuring conversational quality; they're autonomy benchmarks measuring sustained, independent work over extended periods. The value has migrated decisively toward autonomy.
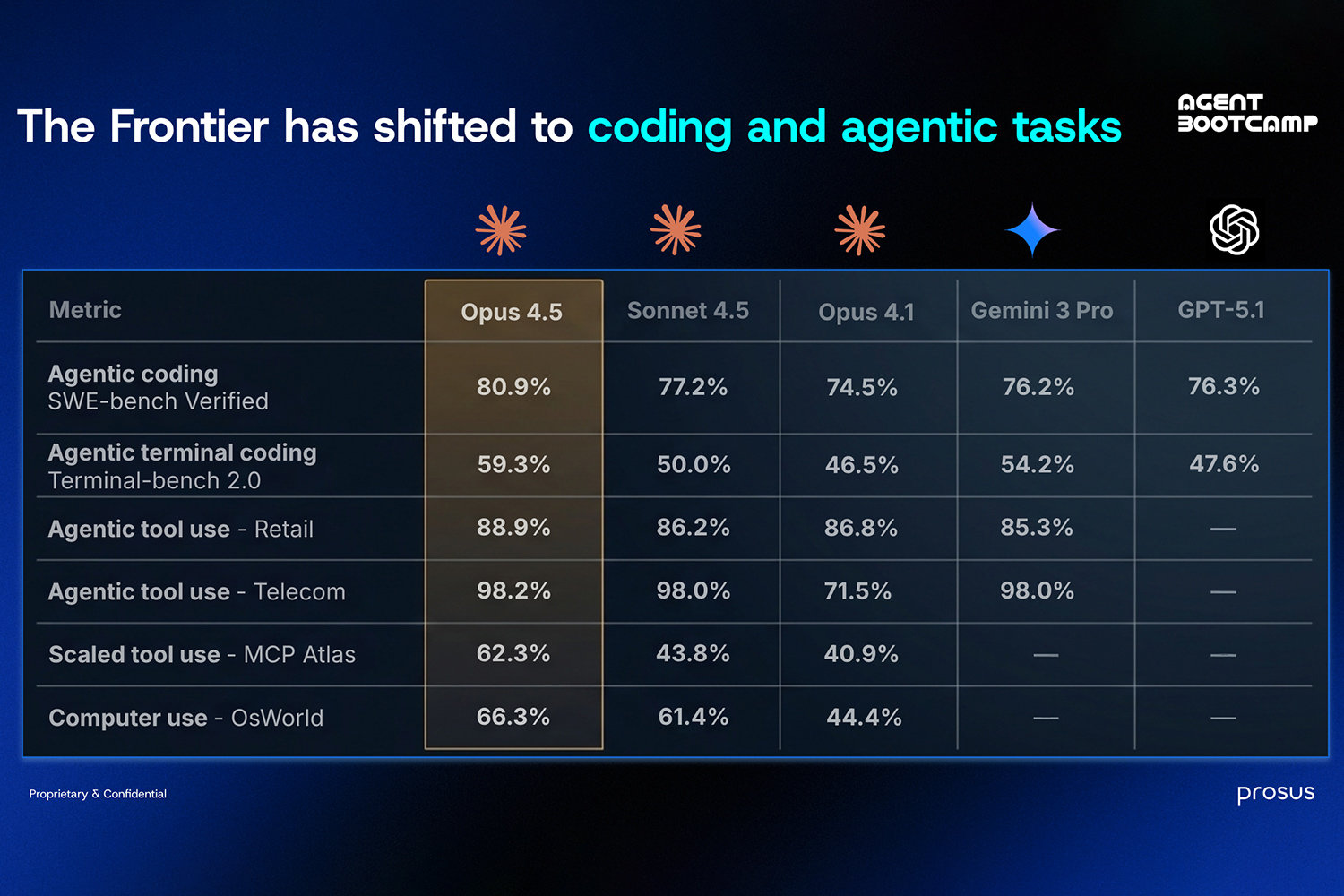
Benchmark for coding and agentic tasks
The uncomfortable truth about model commoditisation
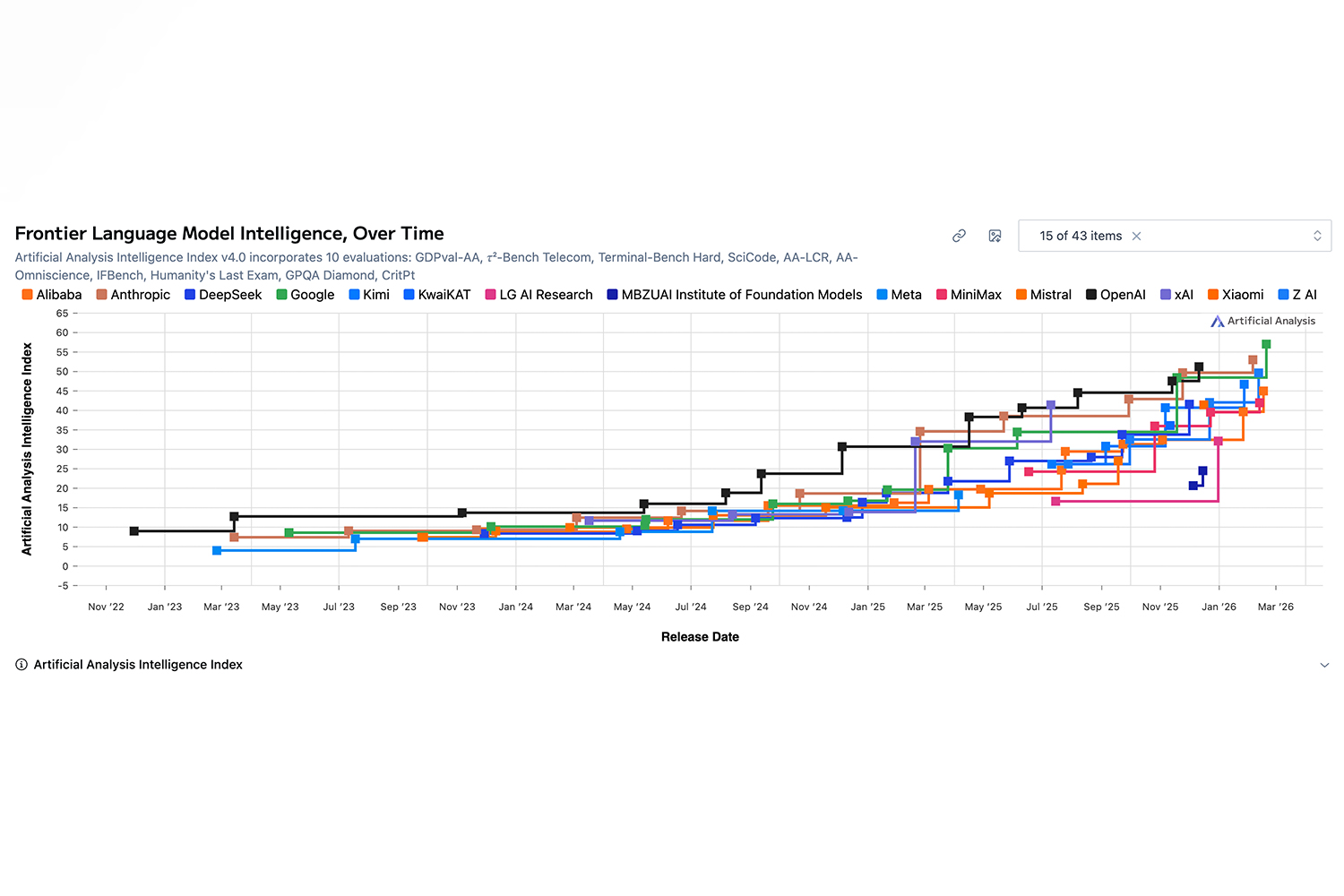
When you plot model performance across major AI labs, the picture is striking. OpenAI's initial lead was enormous, but today the field is crowded. There was a ten-day window in December where Anthropic and Google topped the benchmarks before OpenAI reclaimed the lead by a narrow margin.
When everyone has a frontier model, intelligence becomes a commodity. If your moat is "we have a smarter model," that's no longer defensible.
The real value has migrated to the orchestration layer and application logic. Meta's $2 billion acquisition of Manus makes this clear – Manus didn't have a foundation model, but they had built an exceptional agent orchestration layer. Every team building agents is effectively building their own orchestration layer. When they get it right, that's where defensible value sits, not in the increasingly commoditised model intelligence.
The terminal as the interface of autonomy
One of the most unexpected developments of 2025 was the terminal – computing's geekiest artifact – emerging as a general-purpose interface for autonomy. Claude Code pioneered this, and remarkably, even non-technical people began using the terminal for tasks like research for their holidays.
As Boris Cherny, Claude Code's creator, puts it, Claude Code works because it combines the best model with the best agentic harness. At its core, the harness follows a simple loop: gather context, take action, verify results, repeat. But the power lies in the capabilities enabling each phase – executing bash commands, managing filesystem memory, shifting between planning and execution, invoking reusable skills, orchestrating sub-agents, and verifying results through browser operations. Composed together around a frontier model, these create an agent that can sustain complex work over extended periods.
January 2026: The Acceleration Continues
If 2025 was remarkable for agents, January 2026 proved the pace is only accelerating, with more developments in one month than entire quarters last year. It was a particularly big month for Claude: Claude Code running in loops (the "Ralph Wiggum Loop") delivered surprisingly large performance gains, CoWork brought Claude Code capabilities to non-engineers, and Claude Code Tasks enabled true sub-agent swarms by letting agents share context across parallel sessions.
Clawdbot (now OpenClaw) went viral – an open-source AI agent that runs locally on your machine, controls your browser, terminal, and files, and talks to you through WhatsApp or Telegram – signalling massive pent-up demand for a proactive, always-on life assistant.
And then Moonshot AI released Kimi 2.5 with a special Agent Swarm mode, which represented a meaningful shift. For the first time, a model was trained through reinforcement learning to decide when to launch sub-agents.
Breaking the time barrier
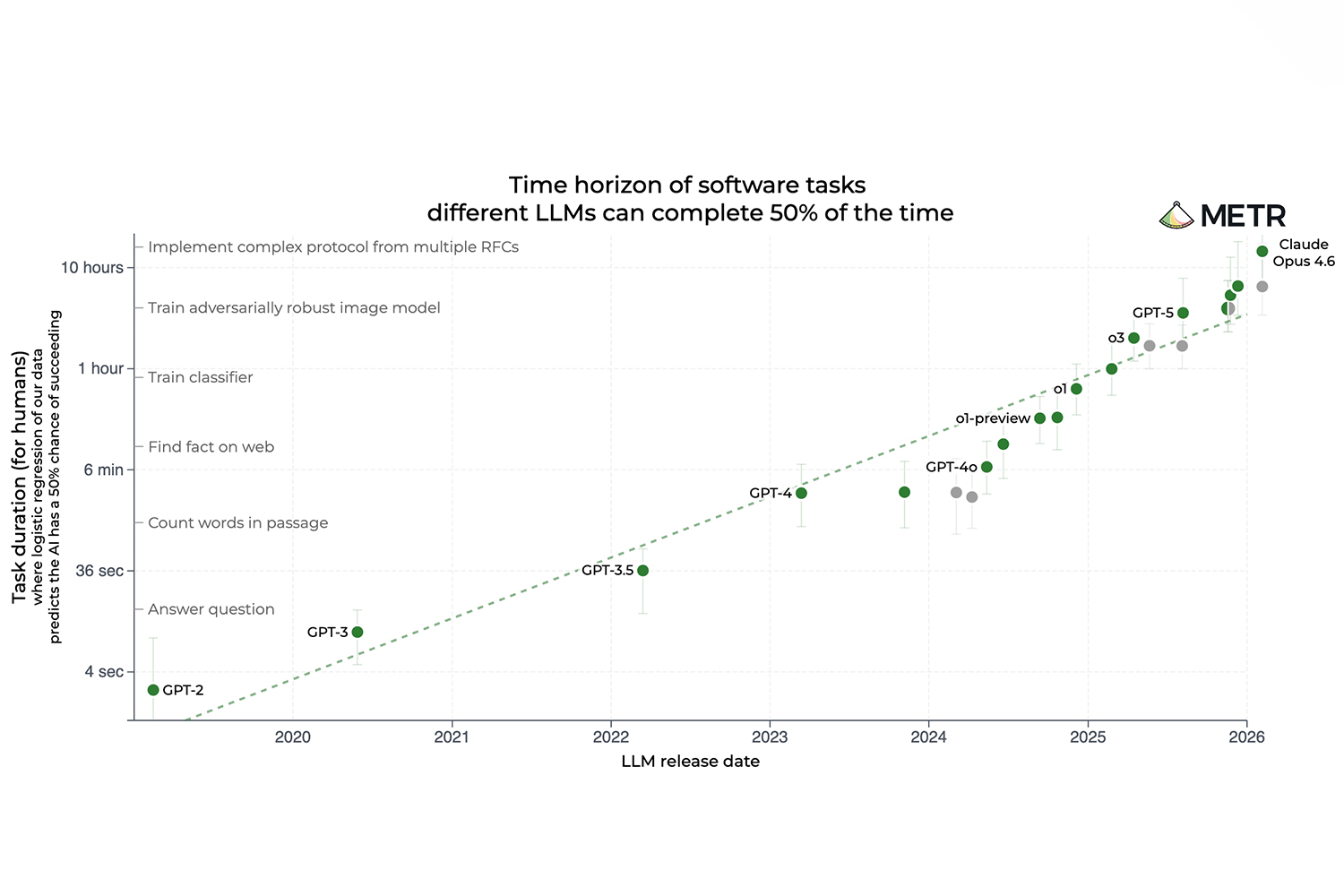
Perhaps the most important trend to understand is the ability of newer models to handle progressively longer, harder tasks. Moving from 15-second questions to hour-long machine learning training sessions means increased complexity, as agents must maintain context across hundreds of steps while preventing compounding errors.
The latest frontier models can work autonomously for nearly five hours. And not only that – the doubling time for task length is roughly 196 days, meaning every six months, the duration of work an agent can handle autonomously is doubling. Extrapolate that forward and the implications are staggering: the era of long-horizon tasks is here.
All agents are coding agents
You might think these advances only matter for coding agents. The truth is that any agent can be represented as a coding agent if you give it access to a terminal and filesystem. And once you do, it benefits from all these advancements.
Imagine a finance agent that pulls portfolio data from APIs, runs valuation models in Python, writes a report and emails it, orchestrating hundreds of steps without human intervention. Or a customer support agent that doesn't just answer questions but diagnoses issues by querying databases, reproducing bugs in a sandbox, and proposing fixes.
None are "coding agents" in the traditional sense, but all benefit from the same agentic harness – terminal access, filesystem memory, sub-agent orchestration, verification loops – that make coding agents powerful. The terminal is how agents control software, but the use case is yours to define.
Three Takeaways
1. Production-grade autonomy is here now. With the right model and harness, agents maintain focus for hours. We're past the prototype stage – this is infrastructure deployed in real business environments.
2. Code is becoming the universal interface of autonomy. The terminal is how agents control software systems across all domains. Give an agent a filesystem and shell, and it inherits every advancement the coding world has made.
3. As models commoditise, build the orchestration layer. The real value isn't in slightly smarter models, it's in the agentic harness itself. Context management, evaluation frameworks, memory architectures, and orchestration logic are where you build competitive advantages.
At Prosus, we see this play out daily across a portfolio spanning four continents, and from food delivery to classifieds to travel. The teams building great agents aren't waiting for smarter models. They're investing in the harness, the orchestration, and the infrastructure that turns autonomy from a demo into a business outcome. That was the lesson of 2025 and the opportunity of 2026. Autonomy is here. Let’s build for it.
Note: As I finalised this article, both Anthropic and OpenAI released new frontier models on February 5, 2026. Claude Opus 4.6 introduces agent teams, a 1 million token context window, and adaptive thinking. GPT-5.3-Codex is OpenAI's first model that helped debug its own training run. Both push the frontier of autonomous work. The race is intensifying—in one direction: autonomy.


